Sobre mí
Bienvenido a mi web personal. Me llamo Manuel Torres, y soy profesor universitario e investigador. Además, desarrollo proyectos relacionados con la ciencia de datos.
En ésta web encontrarás aplicaciones interactivas, artículos interesantes y algunos proyectos que he ido desarrollando a lo largo de los años.
- Seminarios: en ésta página aparecen listados los materiales para algunos seminarios que he impartido en distintas universidades.
Contenido en la web
Seminario minería de texto
Apuntes para el Seminario de Minería de Texto impartido para los alumnos del Máster de Metodología en la UNIR. La minería de texto resulta de gran utilidad en investigaciones cualitativas ya que permite reutilizar el material recogido durante el desarrollo de las mismas, que normalmente se encuentra en formato de texto. Se introducen algunos conceptos de la minería de textos, así como un ejemplo práctico de la aplicación de éstos procedimientos con el lenguaje R.
Reproductor de vídeo
Ésta página permite reproducir cualquier vídeo alojado en internet. Para probar la funcionalidad se muestra un vídeo libre de copyright.
¿Qué es un electroencefalograma?

En éste artículo se proporciona una introducción a los electroencefalogramas (EEG). Se describen los distintos tipos de EEG, su integración en diseños experimentales y se mencionan algunas técnicas y herramientas para analizar los datos que provienen de la prueba.
Seminario gestión del conocimiento
Apuntes para el Seminario de gestión del conocimiento impartido para los alumnos del Máster de Metodología en la UNIR. En el seminario se tratan algunos conceptos teóricos relacionados con el tema, y se discuten varias tecnologías para ponerlos en práctica. Se introduce el software Zotero, que permite gestionar todo tipo de recursos y fuentes de información, además de servir como gestor de referencias. También se describe el sistema de toma de notas Zettlekasten y Zettlr, un editor de texto basado en markdown que permite implementarlo cómodamente.
Copias de seguridad
En éste artículo se habla sobre la importancia de las copias de seguridad para garantizar la integridad de nuestros datos y se comentan algunas tecnologías relacionadas con el tema.
Seminario almacenamiento de datos

Apuntes para el Seminario de almacenamiento de datos impartido para los alumnos del Máster de Metodología en la Universidad Complutense. El seminario está centrado en las distintas maneras de almacenar datos estructurados. Se presentan algunas nociones sobre procesamiento de datos con R y algunos de los formatos de archivo más comunes para almacenar datos estructurados. También se introducen conceptos de las Bases de Datos Relacionales mediante el gestor SQLite.
¿Qué es Nextcloud?
Nextcloud es una solución que nos permite tener nuestra propia nube. Proporciona una alternativa a servicios como Google Drive y OneDrive, con la ventaja de que nosotros mismos controlamos los servidores que gestionan nuestros datos, con todas las ventajas que ello implica para la Privacidad y seguridad de nuestros datos.
Árboles de decisión
Los árboles de decisión son algoritmos que generan reglas que nos permiten asignarle etiquetas a una serie de observaciones de forma automática. Vemos cómo utilizar éstos modelos en Python.
Prueba T para una media

Vemos cómo se aplica la prueba T para una media con R, comprobando el cumplimiento de los supuestos. Además, presentamos una función que automatiza el proceso, aplicando la alternativa no paramétrica en caso de que no se cumplan.
Dashboard desempleo
SELECT en SQL
Vemos cómo utilizar el comando SELECT en SQL, así como las claúsulas WHERE para aplicar filtros y ORDER BY para ordenar los resultados. Explicamos también los principales operadores lógicos en SQLite para crear condiciones que se pueden utilizar para filtrar los datos
¿Qué es la investigación cualitativa?
Vemos en qué consiste la Investigación Cualitativa, y hablamos de las diferencias con otras técnicas de procesamiento de información no numérica.
Práctica Transformada de Fourier
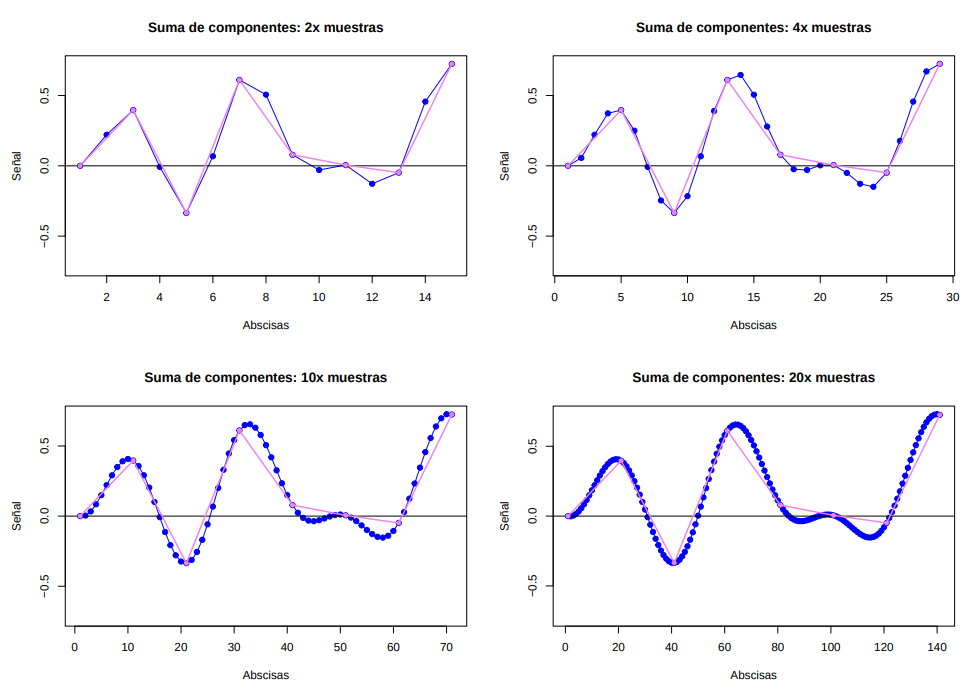
Práctica del máster de la asignatura Análisis de Señales y Sistemas sobre la Transformada de Fourier. En el apartado 5 se desarrolla una implementación en R que permite obtener las señales componentes, así como generar ondas con una resolución configurable que pasan por una serie de puntos.
Primeros pasos con SQL
Primer artículo en la serie de tutoriales de SQL desde cero. Ponemos en marcha el entorno de desarrollo para ejecutar consultas y creamos nuestra primera base de datos.
Visualizar correlaciones

Aprende a crear Gráficos a partir de matrices de Correlaciones con R para visualizar las relaciones entre varias variables. Utilizamos el paquete corrplot y la librería igraph para ver la matriz como una red.
Generador números aleatorios
Genera uno o varios números aleatorios entre un mínimo y un máximo.
Normalización de datos
Explicamos un concepto fundamental de las Bases de Datos Relacionales: la normalización de datos.
Escalamiento multidimensional con R

Utilizamos R para aplicar la técnica del escalamiento multidimensional sobre un fichero que contiene las distancias entre algunas ciudades españolas. Vemos cómo es capaz de organizar las ciudades en el espacio para reconstruir el mapa de España.
¿Qué es SQL?
Primer artículo en la serie de Bases de Datos Relacionales. Hablamos sobre el estándar SQL, que define entre otras cosas la sintaxis para interactuar con éstas Bases de Datos. Vemos que es un gestor de bases de datos y algunos otros conceptos relacionados con éstas tecnologías.
Crear páginas web con python
Hablamos sobre las tecnologías que he usado para crear la página y el papel que tiene cada una. Al final hay un pequeño rant...
TFG Minería de Texto

Trabajo de Fin de Grado sobre el análisis bibliométrico en Psicología. El objetivo del proyecto era estudiar la evolución de la investigación en psicología a partir de los datos disponibles de forma libre en Scopus, una base de datos de artículos científicos. Para ello, en primer lugar tenía que descargar los artículos de la base de datos, lo que implicaba interactuar con la API. Ésta tarea la desarrollé en Python. Los datos se almacenaban en una base de datos de SQLite y el análisis de los datos lo hice con R, presentando los resultados mediante Gráficos interactivos de plotly.
Estadística R markdown Bases de Datos Minería de Texto Aprendizaje no supervisado
Práctica TRI (Ítems dicotómicos)
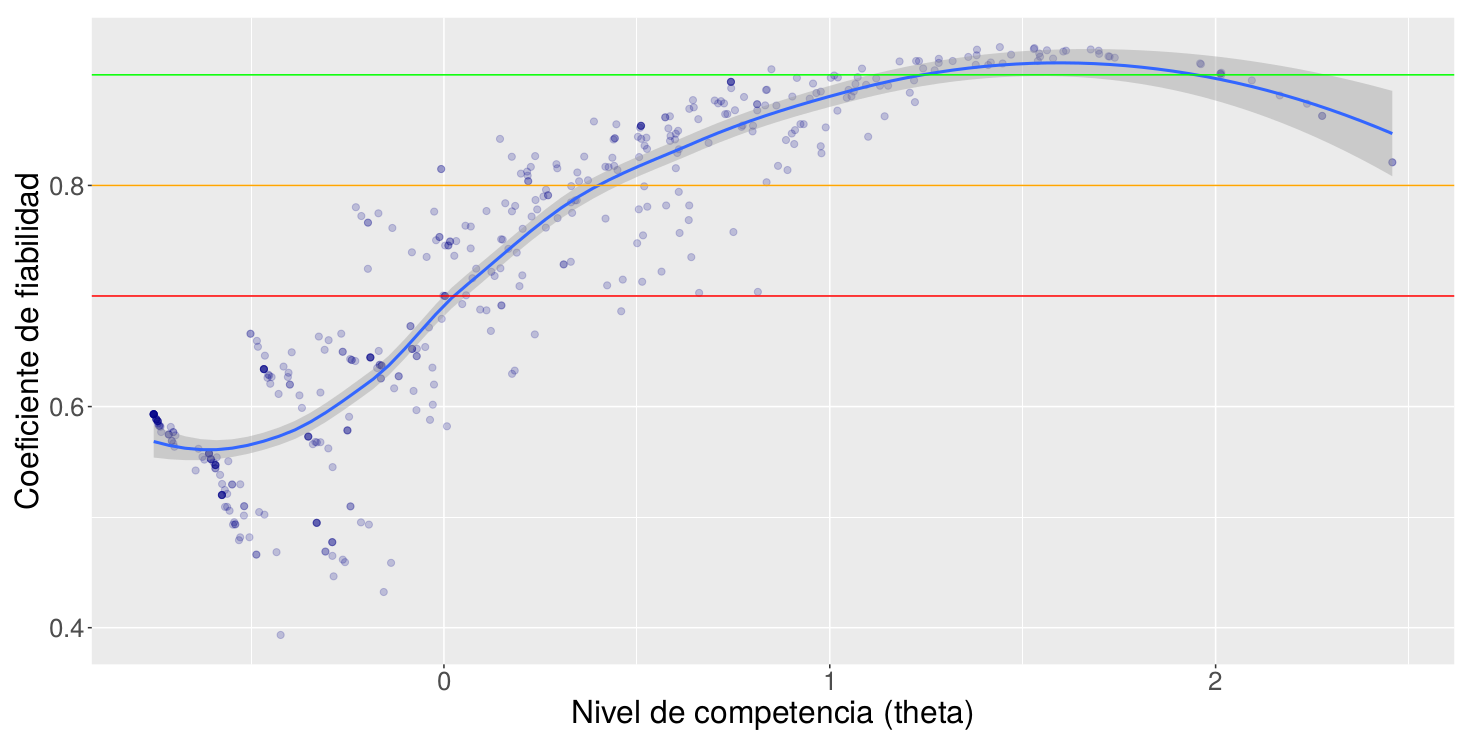
En éste informe se aplica un modelo TRI para ítems con dos opciones de respuesta (acierto/fallo). Ajustamos los modelos de 1, 2 y 3 parámetros, evaluando el ajuste relativo y absoluto de cada modelo. Comparamos las mediciones de la TRI con las de la TCT y comprobamos si efectivamente conseguimos la invarianza de medida.
Práctica TCT
Analizamos las propiedades psicométricas de un instrumento psicométrico mediante la óptica clásica: discriminación de los ítems, comportamiento de los distractores, Consistencia interna y Fiabilidad.
Práctica TRI (Ítems politómicos)
En éste informe se aplica un modelo TRI para ítems con varias opciones de respuesta (una escala graduada).
Simulación factorial confirmatorio
Otra práctica de simulación de temática libre, en éste caso para el Análisis Factorial Confirmatorio. Estudié el cambio en los indicadores de ajuste/desajuste a medida que se van introduciendo errores de especificación en el modelo. La segunda parte de la práctica consistía en realizar un Análisis Factorial multigrupo para determinar si existe invarianza de medida en un instrumento.
Simulación factorial exploratorio
En ésta práctica teníamos que estudiar el comportamiento del Análisis Factorial Exploratorio realizando algunas simulaciones de temática libre. Yo escogí estudiar el efecto del tamaño muestral y el valor de los pesos factoriales simulados sobre la calidad de la recuperación de los pesos y los valores del MSA (de la técnica KMO).
Práctica TDS
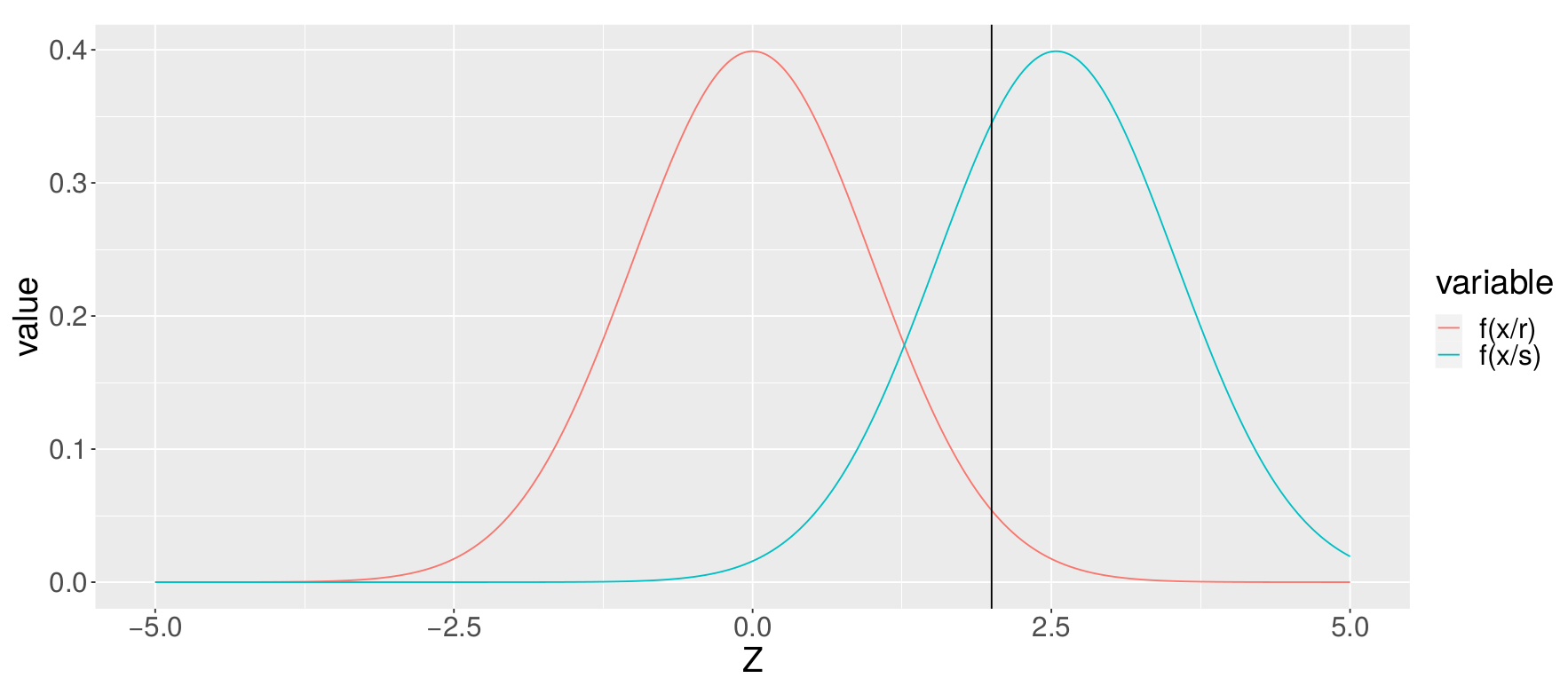
Una práctica sobre la detección de señales mediante la cual estudiamos el patrón de respuesta de varios observadores. Ésta técnica puede utilizarse también para evaluar el rendimiento de modelos de clasificación dicotómica.
Práctica detección de contornos
En ésta práctica de Tecnología del Conocimiento conseguimos marcar los contornos de algunas imágenes. También se realizan algunas tareas de procesamiento de las imágenes comunes en la Visión Artificial. En principio el material estaba pensado para realizar los ejercicios con Matlab, pero se podía utilizar cualquier otra herramienta. En mi caso, decidí trabajar con R.
Ventas target
Práctica árboles de decisión
Una práctica en la que se ajusta un árbol de decisión con R.
Intermedio Programación Machine Learning Ciencia de Datos Aprendizaje supervisado
Comunicado accionistas LVMH
Prueba API json
Saludo
Una sencilla app que muestra las capacidades de django para generar contenido de forma dinámica.